

Le développement actuel des blockchains publiques comme privées est très similaire à ce qu’a connu internet à ses débuts. Internet était en effet un ensemble d’intranet, c’est à dires des réseaux privés généralement attaché à une institution ou à un groupe de personnes travaillant sur un même sujet. Or ces intranets fonctionnaient en vase clos sans possibilité de communiquer les un avec les autres et partager des informations.
Au début des années 70 est apparu le protocole TCP/IP qui a été créé pour relier ces réseaux et permettre la communication inter-network (d’où « internet »). Il en va de même actuellement avec les réseaux reposant sur une blockchain. Même les réseaux publics, c’est à dire ouvert à tous comme le réseau bitcoin, fonctionnent indépendamment des autres réseaux publiques sans possibilité de communiquer directement entre eux. En l’état actuel de la technologie, il n’est pas possible d’échanger directement des bitcoins pour des Ether (émis par Ethereum une autre blockchain publique). Il est uniquement possible d’acheter des Ether avec des bitcoins sur un échange de cryptomonnaies qui met en relation des acheteurs et des vendeurs.
Avant de décrire les solutions imaginées jusqu’à aujourd’hui pour connecter ces différentes blockchain (II), il semble intéressant de décrire brièvement la façon dont internet, ainsi que les applications qui l’utilisent, sont organisés et communiquent les informations (I). Cela nous permettra également de mieux comprendre comment les réseaux décentralisés utilisent la structure existante d’internet pour se développer.
I – CIRCULATION DE L’INFORMATION ENTRE DEUX APPLICATIONS SUR INTERNET
1 – LA PILE GENERIQUE D’UNE APPLICATION REPOSANT SUR LE RESEAU INTERNET :
Le réseau internet tel que nous le connaissons actuellement fonctionne grâce à plusieurs couches d’une même pile qui peuvent être schématisées comme suit :

Chacune de ses couches inclus un ou plusieurs protocoles qui ont pour objectif de sélectionner et préparer l’information avant son envoie à travers internet.
Il suffit de suivre les flèches pour comprendre le parcours de l’information à travers ces piles depuis l’envoie jusqu’à la réception de l’information. L’information part du haut de la pile qui est à l’origine de l’envoie et traverse les différentes couches des deux piles pour aboutir à son destinataire.
La première couche est celle de l’Application qui représente l’interface avec l’utilisateur d’internet. Prenons l’exemple d’une boite mail, une application que nous utilisons tous. Le fait de rédiger un e-mail et de cliquer sur le bouton « envoi » déclenche le processus d’envoie des données à votre destinataire. Votre e-mail sera envoyé en utilisant un protocole appelé SMTP (Simple Mail Transfert Protocol). Un protocole est une liste de règles et étapes permettant une bonne communication entre plusieurs ordinateurs. Il existe de nombreux types de protocoles et le choix du protocole dépend de la couche et du type de données envoyées. Pour des raisons de clarté nous nous limiterons aux protocoles les plus utilises. Au niveau de l’Application, le protocole FTP (File Transfer Protocol) sera utilisé si vous envoyez des fichiers ou encore HTTP (HyperText Transfer Protocol) si vous envoyez une requête sur le web (par exemple une recherche Google).
La couche suivant est la couche de Transport dont l’objectif est d’organiser le transport du message sans prendre en compte (à ce stade) le type de réseau qui acheminera le message. Le protocole le plus courant dans la couche de transport est « TCP » (pour « Transmission Control Protocol ») dont l’objectif est notamment de segmenter le message en plusieurs paquets pour pouvoir les envoyer séparément sur internet, de contrôler que tous les messages arrivent bien en ordre, envoyer à nouveau les paquets ne sont pas arrivés et vérifier que le réseau n’est pas congestionné.
Si nous nous situons maintenant du côté de la partie qui reçoit le message, le rôle du protocole TCP est de collecter les paquets et de les réassembler pour reconstituer le message.
La couche Internet a pour objet d’envoyer les paquets que nous venons de décrire à travers le réseau internet. Pour ce faire, le protocole « IP » (pour « Internet Protocol ») réalise deux actions principales. D’abord, il identifie le destinataire grâce à son adresse « IP » ainsi que sa localisation. Ensuite il envoie les paquets au serveur le plus proche du destinataire final.
Enfin la couche la plus basse de la pile est le Réseau dont l’objectif est de transmettre le message physiquement, en utilisant les infrastructures du réseau internet (Wifi, câble téléphonique, fibre optique…).
Vous trouverez ci-dessous un petit résumé des différents protocoles utilisés selon la couche de la pile du réseau internet :

2 – LA PILE GENERIQUE D’UNE APPLICATION TRADITIONELLE:
Nous nous concentrons ici sur le premier étage de la pile générique, la couche « Application ». Les trois éléments constitutifs d’une application sont la mise en mémoire des données, le traitement et la communication de ces données.
- La mise en mémoire des données.
Il est avant tout important de bien dissocier le « système de fichiers » («files system») de la « base de données » («database»). Le premier système est un ensemble de programme qui permet d’ajouter et de classer des dossiers sur le disque dur d’un ordinateur tandis que le second est un ensemble de programmes qui permettent d’organiser et maintenir une base de données.
Un Système de fichier est moins complexe dans la mesure où il est étudié pour stocker des données non structurées, c’est à dire que toutes reposent sur des formats différents les uns des autres. Par exemple certains fichiers seront en Word d’autre en PDF, mais ne partageront pas une structure commune. Il s’agit donc simplement d’ajouter ces données dans des fichiers et organiser ces fichiers en vue de retrouver les données facilement (à travers un index par exemple), comme vous le feriez avec n’importe quel ordinateur.
Il en va différemment avec un système de management de base de données dans la mesure où il organise des données ayant une structure similaire auxquelles on peut appliquer une logique d’organisation généralement sous forme de tables. En d’autres termes, il est possible de créer un programme (reposant sur un langage comme SQL par exemple) qui va gérer le stockage automatique des données et toutes autres opérations nécessaire à la gestion de ces données. Pour cette raison ce type de système comme MongoDB, MySQL et Cassandra, est plus complexe à mettre en place, mais très adapté lorsque le nombre des données à gérer et le nombre des utilisateurs qui doivent y accéder est important. Créer des logiques de gestion permet en effet d’éviter de dupliquer les donner et sécurise fortement le système.
Pour autant se pose toujours le problème de l’accès et de la mise à jour de ces données lorsque plusieurs applications utilisent la base de données en même temps. Le problème est de parvenir à ordonner l’utilisation de la base de données par ces différentes applications pour assurer que celles-ci n’utilisent que la dernière version mise à jour et n’insèrent pas leurs changements dans une version dépassée. Des procédés mieux connus sous le nom de « contrôle concourant de versions multiples » (de l’anglais « multiversion concurrency control ») visent essentiellement à répartir l’utilisation d’une base de données selon les besoins de telle ou telle application et en permettant son accès simultané.
En pratique, les applications envoient des transactions pour modifier la base de données. Les mécanismes de contrôle concourant de versions multiples ont pour mission d’organiser ces transactions et d’éviter tout conflit. Comme nous allons le voir, le mécanisme de consensus d’une blockchain peut être définit comme un mécanisme distribué de contrôle concourant de versions multiples.
2. Le traitement des données
Le traitement des données correspond à l’ensemble des opérations réalisées par l’ordinateur sur les données. Cette définition couvre par exemple la transformation des données en information lisibles par la machine ou encore la circulation des données à travers les processeurs et les mémoires.
Selon les applications, ce traitement des données peut être effectué avec ou sans enregistrement de l’état de cette information. Pour simplifier n’importe quel ordinateur est une « state machine » (littéralement une « machine d’état »). C’est-à-dire qu’un ordinateur vérifie en permanence si une instruction lui a été soumise en faisant fonctionner une « state fonction ». Chaque fois qu’une requête lui est soumise, l’ordinateur détecte ce changement d’état et l’actionne. Par exemple lorsque vous appuyer sur une icône pour activer une application, votre ordinateur va lancer l’application et une fois complété, enregistrer que l’état de l’application est maintenant « activé » jusqu’à ce que vous décidiez de fermer l’application auquel cas l’ordinateur enregistrera le nouvel état relatif à cette application.
Lorsqu’une commande est seulement actionnée mais que le nouvel état n’est pas enregistré, nous parlons d’un programme, d’une application ou d’un protocole sans état (« stateless »). La différence entre les deux réside dans le fait d’enregistrer ou non les conséquences de l’action qui vient d’être menée.
3. La communication
Comme nous l’avons décrit plus haut, les protocoles TCP et IP ont été imaginés pour connecter les différents réseaux en permettant la circulation des données.
Pour autant, ces protocoles transmettent les données de la même manière quelque soit leurs valeurs. Le protocole décompose l’information en paquets et les envoie jusqu’à ce qu’il ait reçu la confirmation que tous les paquets ont été reçus et reconstitués par le destinataire.
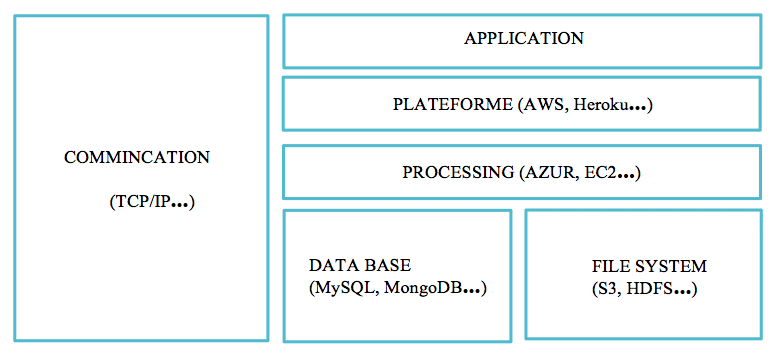
3 – LA PILE GENERIQUE D’UNE APPLICATION DECENTRALISEE:
Les applications décentralisées reposant sur une blockchain ne sont pas totalement différentes dans leur structure des applications traditionnelles que nous venons de décrire. Nous avons identifié les différentes composantes d’une application pour pouvoir les comparer avec celles d’une application décentralisée. Notez que nous nous reposerons sur le protocole bitcoin mais aussi et surtout sur Ethereum pour illustrer les différentes strates d’une application décentralisée puisque cette dernière plateforme a été créée pour développer des applications décentralisées.
- La mise en mémoire
Comme nous l’avons déjà évoqué, une blockchain est une base de données d’un genre nouveau puisqu’elle est à la fois décentralisée, transparente et protégée par des procédés cryptographiques.

Nous venons d’expliquer ce qu’est un mécanisme de contrôle concourant de versions multiples, le rôle d’une blockchain et du mécanise de consensus qui y est attaché est le même, à la différence qu’elle le réalise de manière décentralisée.
Son rôle premier est en effet d’organiser l’ajout des transactions à la blockchain. Les réseaux reposant sur une blockchain sont par définition décentralisés. Cela signifie que ce sont les membres du réseau qui mettent à jour la base de données du réseau et non plus un tiers de confiance. Toute la difficulté de ce mode de fonctionnement est de parvenir à s’assurer que les transactions sont bien ajoutées à la blockchain une seule fois selon un ordre qui convient donc à tous les membres du réseau. Il est en effet vital pour la pérennité du réseau qu’une transaction qui a été ajoutée à la blockchain ne le soit pas une seconde fois. Il s’agit en fait d’éviter le problème de la double dépense.
Imaginons en effet que le bitcoin que vous venez de recevoir a également été reçu par une autre personne, le transfert de valeur sur internet qui est la raison d’être du réseau bitcoin serait immédiatement remise en question.
Lorsque les membres d’un tel réseau ne se connaissent pas, ce qui est le cas du bitcoin, un mécanisme de consensus est nécessaire pour organiser l’ajout des transactions à la blockchain. C’est-à-dire déterminer lequel des membres aura le droit d’ajouter la transaction et obtenir la récompense (12,5 bitcoins à l’heure actuelle – ce nombre est programmé pour diminuer à intervalles réguliers) qui y est attachée.
Dans l’univers des bases de données, une transaction est un ensemble de changement effectué sur la base de données. Cette affirmation est vraie dans le cadre du bitcoin puisque chaque transactions ajoutées dans des blocks par les mineurs inclus un nouvel output. Cet output sera ensuite ajouté dans l’Input de la transaction suivante qui elle aussi inclura un nouvel Output. Chaque transaction ajoute modifie donc bien la base de données en ajoutant un nouvel output.
Cette affirmation est encore plus vraie dans le cas des plateformes de smart contracts tel qu’Ethereum. Les smart contracts sont en effet enregistrés directement sur la blockchain et sont actionnés par des transactions (commandes envoyées par des comptes externes à la blockchain) ou des messages (commandes envoyées par d’autres smart contracts). Autrement dit, l’état des smart contracts sur la base de données est directement modifié par une transaction.
Dans le cadre des blockchains, le programme en charge de la gestion de la base de données est donc le protocole qui regroupe toutes les règles de fonctionnement du réseau. Son rôle est notamment de définir les règles que devront respecter les transactions pour pouvoir être ajoutées à la blockchain (taille, informations requises, Output valide, clé privée correspondante à la clé publique…).
Dans sa forme initiale (celle du bitcoin), la blockchain est le seul emplacement où sont stockées les données. La blockchain est téléchargée par tous les membres complets du réseau, donc il existe autant de bases de données du réseau qu’il y a de membres complets. Les membres doivent donc la mettre à jour constamment, pour être certain que la base de données dont ils disposent contient bien le dernier block ajouté.
La technologie a beaucoup évolué depuis l’apparition du bitcoin en 2009, et il est aujourd’hui possible de stocker les informations du réseau dans des bases des données qui sont externe au réseau et à sa blockchain. C’est notamment avec IPFS qui communique avec la blockchain grâce à des smart contracts.
2. Le traitement des données
La structure de la blockchain telle qu’elle est apparue en 2009, le blockchain bitcoin, ne propose qu’une décentralisation du stockage des données comme nous venons de l’évoquer. Les deux autres aspects, le traitement des données et la communication, demeurent propre à chaque membre du réseau. Autrement dit, ces activités ne sont pas réparties entre les membres du réseau comme l’est le stockage des données.
Il faudra attendre la création d’Ethereum et de sa machine virtuelle décentralisée pour voir apparaitre la première décentralisation des traitements de données. Contrairement au réseau bitcoin, le protocole Ethereum propose de stocker des transactions dans chacun des blocks de la blockchain, mais aussi et surtout, des programmes informatiques, les fameux Smart Contracts. La blockchain devient donc une base de données douée de capacité de calcul relativement avancée.
Concrètement cela signifie que les programmes informatiques stockés dans la blockchain peuvent être actionnés par des utilisateurs (par des transactions envoyées à partir des comptes externes) ou d’autres contrats (par des messages envoyés à partir de comptes internes). Or les commandes sont actionnées par la Machine Virtuelle Ethereum qui est constituée de tous les ordinateurs des membres du réseau. Quand un smart contract est actionné tous les ordinateurs du réseau exécutent le programme simultanément et mettent à jour le nouvel état du smart contrat dans la blockchain dont chacun des membres dispose également.
Ce qu’il est important de retenir c’est qu’avec Ethereum, nous sommes passé à un deuxième stade de décentralisation dans lequel il est possible de rassembler des milliers d’ordinateurs de personnes qui ne se connaissent pas en vue d’exécuter les programmes d’un réseau planétaire. C’est d’ailleurs la raison pour laquelle Ethereum est parfois surnommé le premier ordinateur mondial. Pour en savoir plus le fonctionnement d’Ethereum, vous pouvez vous reporter à cet article.
3. Une communication Décentralisée
A l’heure actuelle, les applications décentralisées reposent encore sur la pile de communication internet (TCP/IP) pour échanger des informations, mais les évolutions technologiques pourraient changer cette donnée dans un futur proche.
La pile d’une application décentralisée pourrait donc être schématisée de la sorte :

Dans la deuxième partie de cet article, nous décrirons les méthodes de communication inter blockchains.
Si vous avez aimé cet article, n’hésitez pas à la partager sur les médias sociaux!! Merci
Follow me on Social media








